
Artificial intelligence has become a foundational technology for businesses of all sizes—but the performance of AI depends heavily on the model it’s built upon. With new AI models entering the market almost monthly, selecting the right one has become a complex and critical decision.
To ensure our partners have access to the most accurate, efficient, and cost-effective AI experiences, we conducted an internal AI models benchmark comparing the latest releases from OpenAI and Google Gemini.
This blog shares our process, results, and how Vendasta uses this information to keep our platform—and your business—on the cutting edge.
Automate every step of the customer journey with AI employees
Why Benchmarking AI Models Is Essential
AI is not one-size-fits-all. Different models perform differently depending on the use case. While some may excel at generating natural responses, others may offer lower latency or better pricing.
For businesses operating within an AI automation agency business model, benchmarking AI tools such as chat assistants, lead capture bots, and automated support systems is essential to balance cost, performance, and reliability..
At Vendasta, we benchmark AI models to ensure our partners consistently leverage the highest-quality technology available. Our findings help guide which models power our AI employees across the platform. 
What Was Tested in the 2025 AI Models Benchmark
We focused our benchmark on two of the largest and most widely used AI providers—OpenAI and Google Gemini—and compared six of their latest models.
OpenAI Models Tested:
- GPT-4.1: OpenAI’s most advanced model; currently powers Vendasta’s AI Receptionist.
- GPT-4o: A high-performance model previously used in production at Vendasta.
- GPT-4.1 Mini: A cost-effective variant with fewer parameters.
- GPT-4.1 Nano: A lightweight version designed for simple tasks at low cost.
Google Gemini Models Tested:
- Gemini 2.5 Pro: Google’s most capable model as of May 2025.
- Gemini 2.5 Flash: A faster, less powerful version optimized for response speed.
All models were tested using the same complex, real-world scenario from one of our largest AI Receptionist deployments: Mr. Appliance, part of the Neighborly group. This scenario involves verifying warranty status, handling service inquiries, quoting diagnostic fees, and scheduling appointments, making it a robust use case for benchmarking accuracy, latency, and cost.
Methodology: How We Conducted the Benchmark
We used Deepeval, a test suite platform that runs structured tests on AI models using controlled prompts. Our benchmark consisted of 115 tests per model, executed in multiple rounds for consistency. Each model responded to identical inputs under the same environmental conditions.
Google’s Gemini models were evaluated with “thinking mode” enabled—a feature that allows the model to iteratively refine its response. This typically improves output quality, though at the cost of higher latency. OpenAI models were evaluated in standard mode, without enhancements.
Luis Camara, Staff Developer at Vendasta, led this internal benchmark analysis.
Results: Performance Across Accuracy, Latency, and Cost
Below is a side-by-side chart showing how each model performed across key metrics: success rate, latency, and cost.
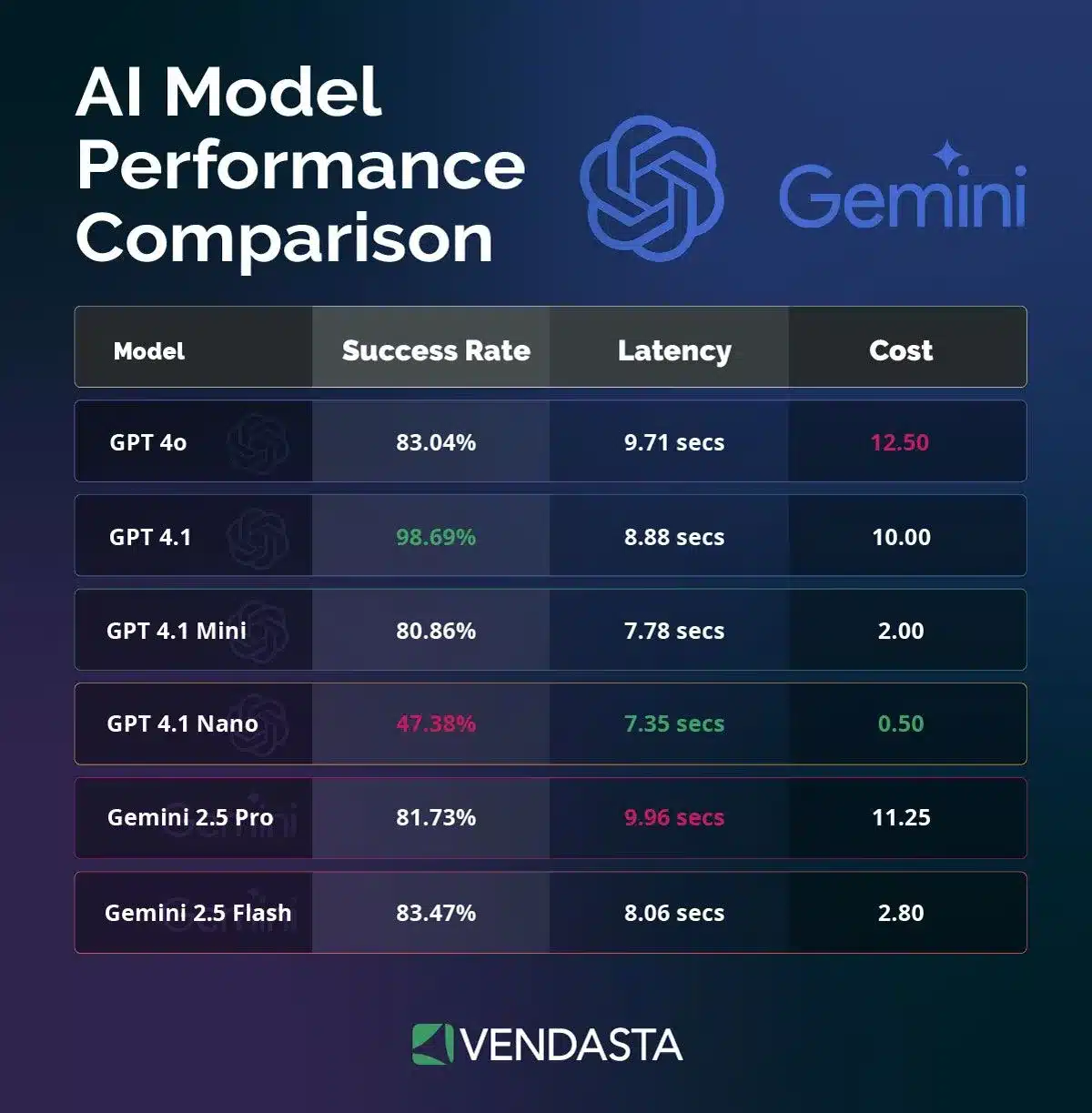
We break down these findings further below, including key takeaways for each AI model:
GPT-4.1: Best Overall Model
- Success Rate: 98.69%
- Latency: 8.88 seconds
- Cost: $10
- Verdict: Outstanding accuracy and reliability; ideal for production-grade conversational AI.
GPT-4.1 Mini: Best Cost-to-Performance Balance
- Success Rate: 80.86%
- Latency: 7.78 seconds
- Cost: $2
- Verdict: A strong contender for budget-sensitive scenarios with moderate complexity.
Gemini 2.5 Flash: Fast and Promising Backup Option
- Success Rate: 83.47%
- Latency: 8.06 seconds
- Cost: $2.80
- Verdict: Outperformed its more expensive sibling (Gemini Pro) and is a viable fallback model.
GPT-4o: Solid Legacy Performer
- Success Rate: 83.04%
- Latency: 9.71 seconds
- Cost: $12.50
- Verdict: Reliable but more expensive and slower than its successors.
Gemini 2.5 Pro: High Cost, Low Return
- Success Rate: 81.73%
- Latency: 9.96 seconds
- Cost: $11.25
- Verdict: Less efficient than Flash despite a higher price and longer wait times.
GPT-4.1 Nano: Not Recommended for Complex Use
- Success Rate: 47.38%
- Latency: 7.35 seconds
- Cost: $0.50
- Verdict: Incomplete responses and inconsistent accuracy; only suitable for very simple outputs.
What This Means for Vendasta Partners
Our AI models benchmark makes it clear: the technology behind our AI tools is carefully selected for your success.
Our AI Receptionist—the most widely used AI Employee on our platform—runs on the highest-performing model available today, and our benchmark process ensures all future AI tools meet the same standard.
Are you new here? Vendasta’s AI Receptionist is a 24/7 conversational assistant that answers questions, qualifies leads, books appointments, and handles customer inquiries directly on your clients’ websites.
Powered by the latest AI models, it helps businesses engage visitors instantly, capture more leads, and never miss an opportunity—even outside business hours.
Looking Ahead: How Vendasta Continues to Evolve with AI
To future-proof our AI infrastructure and keep our partners ahead of the curve, Vendasta has implemented several foundational technologies:
- LangChain Integration: A modular system that allows us to plug into new models and tools rapidly.
- Vendasta AI Provider: A secure, custom-built layer that ensures safe authentication, accurate usage tracking, and vendor-specific configuration.
- Model-Agnostic Pipeline: Our infrastructure can quickly switch between AI models as new advancements emerge.
While many in the industry promote Model Connection Protocols (MCPs) as the future of AI agent integration, the reality is more complex.
As our Staff Software Developer, Dustin Walker, recently noted, most MCPs today are limited to developer-oriented desktop clients, such as Cursor or Claude Desktop. For SaaS platforms like Vendasta—where scalable, secure cloud-to-cloud AI agent integration is essential—these protocols fall short, particularly in areas like authentication and authorization, which are still evolving.
That’s why we built a custom transport layer to connect our AI employees securely with internal APIs. This allows us to maintain security, scalability, and speed while the broader MCP ecosystem matures.
We’re closely following the development of the MCP spec and will adopt community standards as they evolve. Until then, we’re committed to delivering production-ready solutions that work today, not just promising future potential.
The benefit to our partners? You get AI-powered tools that are stable, reliable, and integrated directly into your workflows—without waiting for the rest of the industry to catch up.
Conclusion: Our AI Benchmark Ensures You’re Always One Step Ahead
This benchmark confirms that GPT-4.1 is currently the best model to power AI chat experiences. It combines market-leading accuracy with acceptable latency and cost.
We benchmark, test, and optimize so that you don’t have to. Our mission is to ensure our AI-powered solutions help your business thrive—now and in the future.
Ready to see what our AI employees can do for your business? Request a demo to experience the difference.
AI Models Benchmark FAQs
1. What is an AI model benchmark?
An AI model benchmark is a structured evaluation that compares different AI models based on performance metrics, such as accuracy, latency, and cost, across consistent test scenarios.
2. Why does Vendasta benchmark AI models?
Vendasta benchmarks AI models to ensure its partners and customers always benefit from high-performing, cost-effective AI solutions for automation, communication, and engagement.
3. Which AI model performed best in the benchmark?
GPT-4.1 achieved the highest success rate at 98.69%, making it the top performer for accuracy and reliability in real-world business use cases.
4. Is GPT-4.1 Mini a good option?
Yes. GPT-4.1 Mini offers excellent value with strong performance at a lower cost, making it ideal for cost-sensitive tasks.
5. How did Google Gemini models perform?
Gemini 2.5 Flash outperformed Gemini Pro and showed promising speed and accuracy, but still did not surpass OpenAI’s models in cost-effectiveness or reliability.
6. Are these models available to Vendasta partners now?
Yes. Vendasta’s AI Receptionist currently uses the best AI model, GPT-4.1.
7. What is “thinking mode” in Gemini models?
Thinking mode allows Gemini models to reason through answers more deeply before responding, often improving output quality but increasing latency.
8. How does Vendasta stay current with AI advancements?
Vendasta uses a flexible, model-agnostic AI pipeline integrated with LangChain and its own custom AI provider layer, allowing fast adoption of new technologies.
9. How does this benchmark benefit me as a partner?
It means you can trust that your AI-powered tools are built on thoroughly tested, high-performing models that enhance customer experiences and business efficiency—without needing to do the evaluation yourself.
10. Will Vendasta update its AI models as new ones are released?
Yes. Vendasta continuously evaluates new AI models and integrates improvements. As the ecosystem evolves, partners can trust that the best-performing models will be adopted without manual intervention or service disruption.
